Rでデータの中身をざっと確認する
読み込んだデータをざっと確認したい
データ分析業務を行っていると、定期的に分析対象のデータが変わることは当然発生します。
新たなデータを受け取った時は、データの中身をざっと確認したいことがあります。
とはいえ、そこまでそういった処理の頻度が高いわけでもなく、データが新しくなるたびに処理方法を確認する、ということをしていました。
毎回確認するのは非効率なので、これを気にこの記事に色々な確認方法をまとめておきます。
データのカラム数に応じで、確認方法を分類します
データの中身をざっと確認すると言っても、そのデータのカラム数が5なのか、100なのかによって、適切な確認方法は変わると思います。
そのため、この記事では各データの大凡のカラム数によって、確認方法を分類します。
カラム数が7くらいまで
確認を行うデータは、irisデータにします。
> dim(iris) [1] 150 5 # 150行、5列のデータ > head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.3 0.2 setosa 4 4.6 3.1 1.5 0.2 setosa 5 5.0 3.6 1.4 0.2 setosa 6 5.4 3.9 1.7 0.4 setosa
base::plot(iris)
パッケージのインストールが不要で、記述も簡単です。
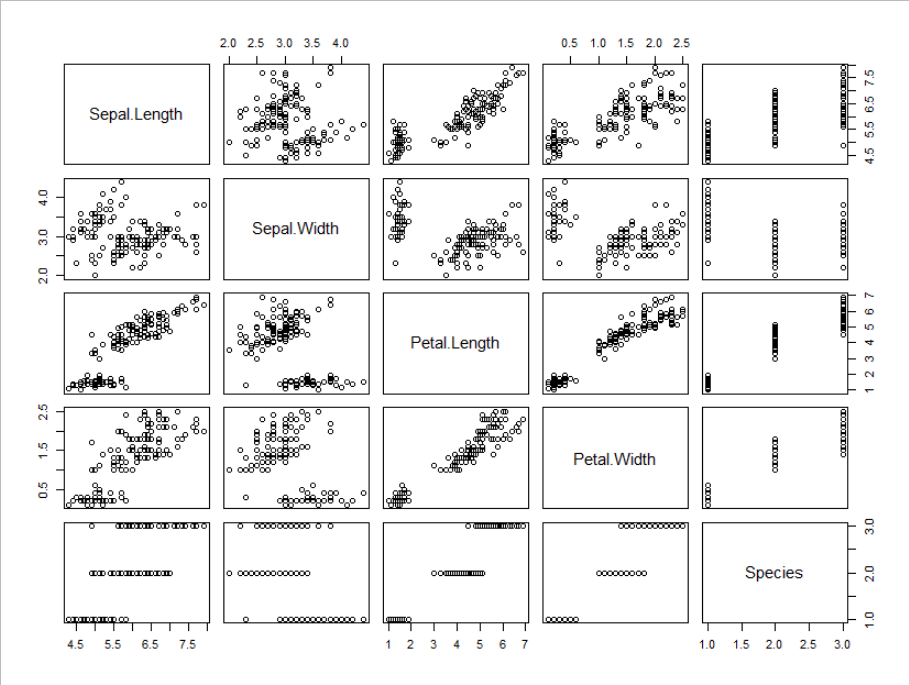
psych::pairs.panels(iris)
変数毎の分布が見れて、かつ2変数の散布図、及び相関係数が確認できます。
記述も簡単なので、お手軽かつデータの概要を掴むのには有効だと思います。
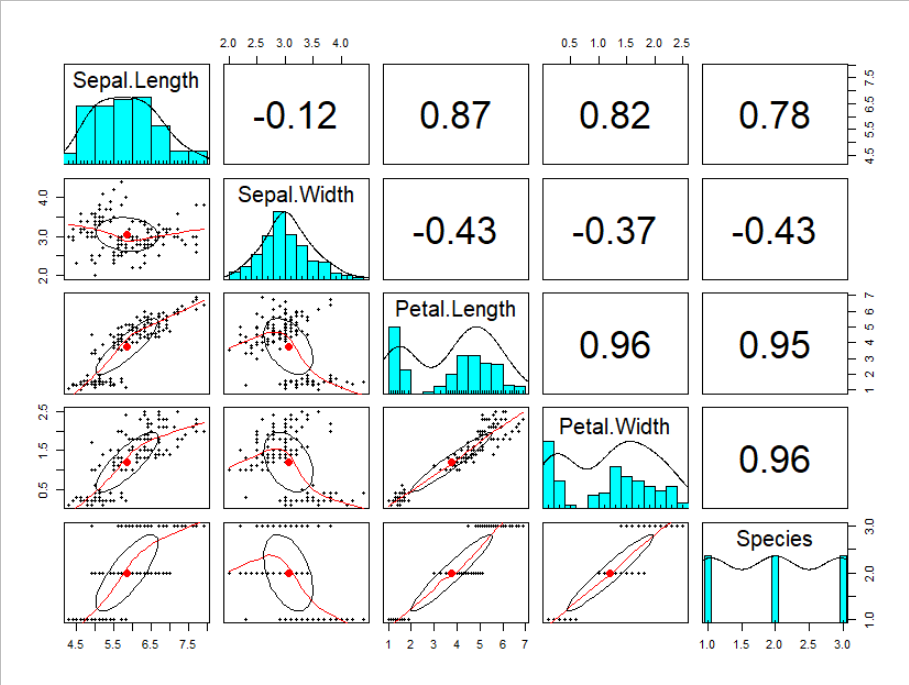
GGally::ggpairs(iris)
若干処理が重いイメージがありますが、綺麗に描画してくれるので個人的に好きです。
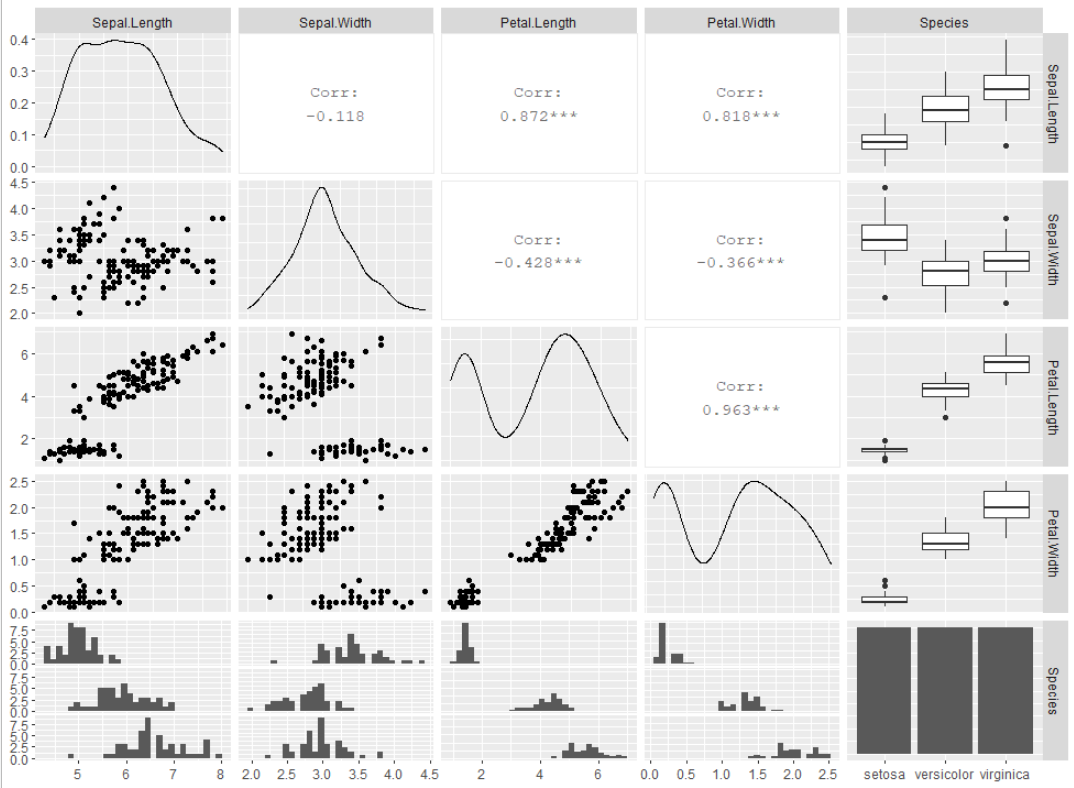
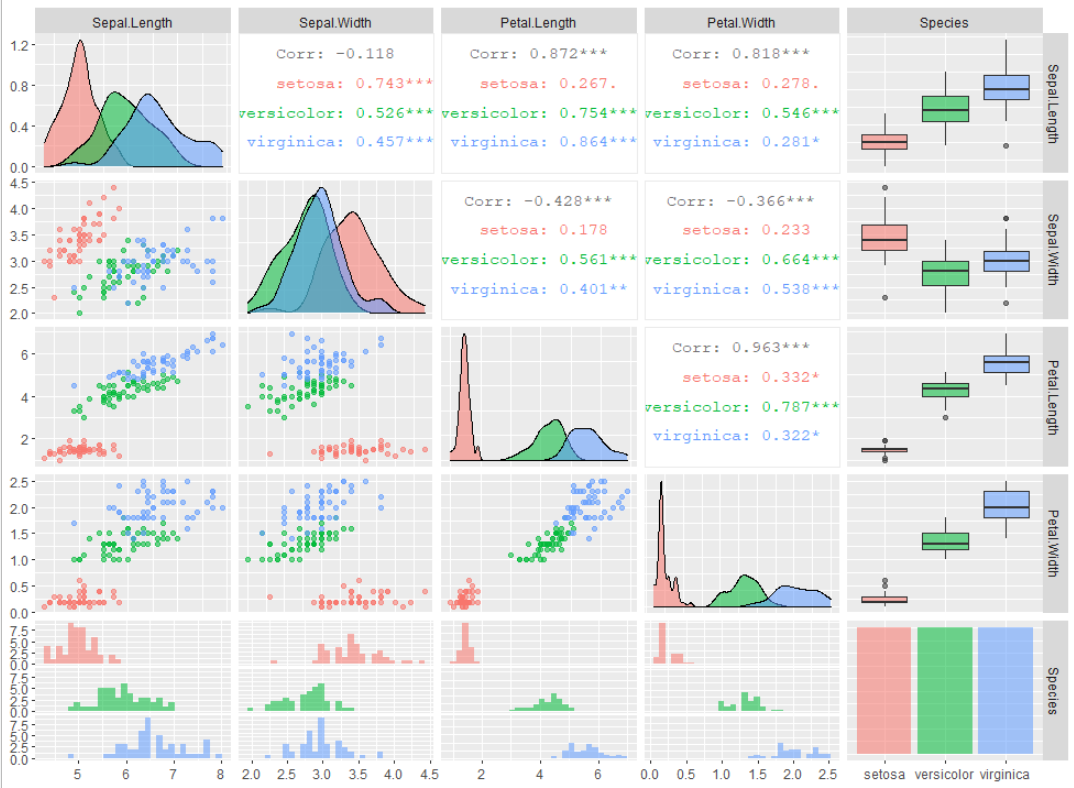
任意の列の値で色分けをしたい場合、以下のように記述すると行えます。
GGally::ggpairs(iris, ggplot2::aes(colour=Species, alpha = 0.8))
カラム数が10以上
カラム数が多くなると、行列形式で全ての値を俯瞰するのはあまり現実的ではないと思います。
その上でできそうなことを書いていきます。
対象データは、DoDStat@d データ指向統計データベース内から、新国民生活指標(住む)データをお借りします。
> dat <- read.csv('http://mo161.soci.ous.ac.jp/@d/DoDStat/PLIlive/PLIliveJ.csv', header = TRUE) > dim(dat) [1] 47 24 > head(dat) Pref NonRep OverMin Rent HomeOwn CompPol NumClime NumLarc TrafAcci Fire DspRubb Sidewalk MedFacil OverOrd Sunshine NumMat AreaResi Transpt AreaPark Sewarage Recycle AmtRubb AvgMin Pavement 1 北海道 7.67 94.3 1510 54.0 15.0 7.6 206 451.8 77.3 44.78 21.7 57.3 53.71 56.16 11.8 306 90.9 25.5 77.86 4.9 1655.0 24 19.9 2 青森県 7.80 95.9 1480 71.6 32.8 4.5 103 558.2 88.1 66.29 10.9 30.1 57.73 61.99 12.6 356 87.1 12.9 36.00 3.2 1363.6 23 24.9 3 岩手県 6.93 95.0 1643 72.8 22.0 6.3 115 388.9 65.6 79.81 8.3 34.1 55.65 72.20 12.4 365 80.2 9.6 35.50 11.3 940.0 24 14.4 4 宮城県 7.26 93.9 2257 60.7 34.3 9.1 272 471.1 81.7 83.99 13.8 49.4 45.44 67.29 10.8 358 85.1 11.7 40.10 16.2 1102.9 29 26.6 5 秋田県 5.92 97.1 1554 79.6 23.1 9.1 88 364.3 84.8 70.43 8.3 31.4 63.89 63.55 13.3 389 84.9 15.8 31.90 10.4 1203.8 22 15.7 6 山形県 5.75 96.8 1701 79.2 31.0 5.6 137 496.6 94.8 81.28 15.0 40.9 54.28 74.52 11.7 398 79.7 13.4 44.60 16.5 950.2 23 20.7
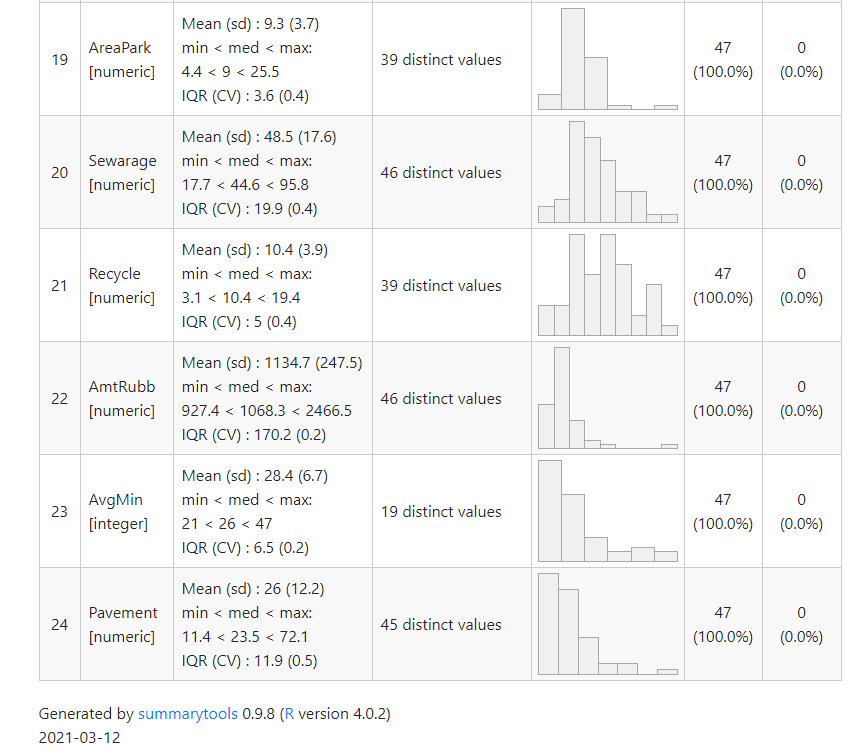
summarytools::dfSummary(dat) %>% summarytools::view()
変数毎に、平均値や最小最大値、分布を表示してくれます。
変数が多くなるとそれだけ出力結果も長くなるので、下図では最初と最後の部分だけを抜粋しています。

~
他にもあれば追加していきます
データをざっと眺めるのは大事ですが、それをするために毎回時間を食ってしまうのはもったいないと思います。
今後も良い確認方法があれば追記していきます。