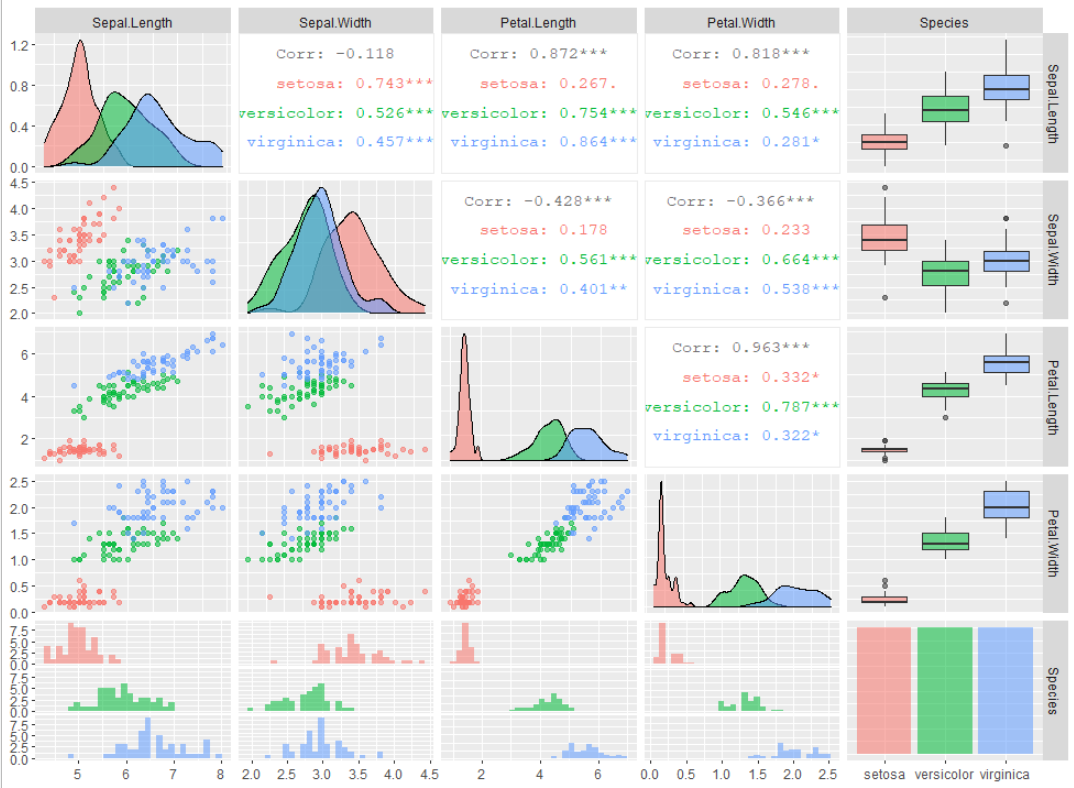
1.4.1 データ準備
施策の効果検証を行う理想的な方法、RCTについて触れています。
使用するデータは、こちらのサイトで公開されているデータです。
このデータについて、書籍では以下のように紹介されています。
P24
このデータセットは、ECサイトのユーザーに対してRCTを適用したメールマーケティングを行ったものです。
データセットの説明は、以下になります。
| カラム名 |
説明 |
| recency |
最後の購入からの月数 |
| history_segment |
過去1年間に消費された金額の分類 |
| history |
過去1年間に購入された実際の金額 |
| mens |
0,1。1 = 顧客が過去1年間にメンズ商品を購入したことを表す。 |
| womens |
0,1。1 = 顧客が過去1年間にレディース商品を購入したことを表す。 |
| zip_code |
郵便番号を都市部、郊外、農村部に分類する。 |
| newbie |
0,1。1 = 過去1年間の新規顧客であることを表す。 |
| channel |
過去1年間に、顧客が購入したチャネルを表す。 |
| segment |
顧客が受け取った、メール内容を表す。 |
| visit |
0,1。1 = メール受信後2週間以内に、ウェブサイトを訪問したことを表す。 |
| conversion |
0,1。1 = メール受信後2週間以内に、商品を購入したことを表す。 |
| spend |
購入金額。単位はドル。 |
このデータセットは、RCTによって得られたデータ、つまりセレクションバイアスが発生していないデータになっているため、単純な集計を用いてメールマーケティングの効果を測定していきます。
library(tidyverse)
library(data.table)
email_data <- fread('http://www.minethatdata.com/Kevin_Hillstrom_MineThatData_E-MailAnalytics_DataMiningChallenge_2008.03.20.csv')
male_df <- email_data %>%
filter(segment != 'Womens E-Mail') %>%
mutate(treatment = if_else(segment == 'Mens E-Mail', 1, 0))
# csvの読み込み
書籍では、
email_data <- read_csv()
となっていますが、宗派の違いで data.table::fread() を使用しています。
以前Tokyo.R で、「fread が早い!」と聞いてから、使っています。
確かに、ローカルにあるcsvを読み込む際は data.table::fread() が早いと感じますが、webからcsvを取得する際はさほど変化がないと思います。まぁ、どちらでも良いでしょう。
# データ抽出
元のデータには、「メール配信なし」「女性向けメール配信あり」「男性向けメール配信あり」の3つのデータがあります。
ただ、メール配信の効果をわかりやすく見るために、「メール配信なし」と、「男性向けメール配信あり」のみのデータにしています。
この後の手順で、「メール配信なし」に比べて、「男性向けメール配信あり」の方が、売上が高いかどうか、といったことを調べていくことになります。
summary_by_segment <- male_df %>%
group_by(treatment) %>%
summarise(conversion_rate = mean(conversion),
spend_mean = mean(spend),
count = n())
summary_by_segment
treatment conversion_rate spend_mean count
<dbl> <dbl> <dbl> <int>
1 0 0.00573 0.653 21306
2 1 0.0125 1.42 21307
# 結果の出力
「treatment = 0:メール配信なし」の conversion_rate が0.573%なのに対して、「treatment = 1:男性向けメール配信あり」の conversion_rate は1.25%あります。
差し引き、0.677%ptの差があり、その差がメールマーケティングの効果になっています。
同様に spend_mean を見ると、前者は0.653ドル、後者は1.42ドルとなり、差分は0.767ドル。
よって、メール配信されたことにより、購入確率も、購入金額も高くなったことがわかりました。
1.4.2 有意差の検定
メールマーケティングの有無で生まれた効果の差に関して、統計的に有意な差があるのかどうかを検証していきます。
mens_mail <- male_df %>%
filter(treatment == 1) %>%
pull(spend)
no_mail <- male_df %>%
filter(treatment == 0) %>%
pull(spend)
「男性向けメール配信あり」と、「メール配信なし」、それぞれの購入金額を新しい変数に代入していきます。
dplyr::pull() はあまり使ったことがありませんでした。
調べると、以下のような書き方をするのと効果は変わりがないですが、パイプ演算の中で記述できる点、処理がわかりやすい点が良いと思います。
※別の書き方
mens_mail <- male_df$spend[male_df$treatment == 1]
作成した2つの変数に関して、t検定を行います。
rct_ttest <- t.test(mens_mail, no_mail, var.equal = TRUE)
rct_ttest
Two Sample t-test
data: mens_mail and no_mail
t = 5.3001, df = 42611, p-value = 1.163e-07
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.4851384 1.0545160
sample estimates:
mean of x mean of y
1.4226165 0.6527894
# 結果の出力
結果を見ると、mens_mail、no_mail、それぞれの平均値がmean of x、mean of y として表示されています。
また、「p-value = 1.163e-07」とp値が非常に小さい値になっていることから、帰無仮説である「平均の差は0である」が棄却され、対立仮説である「平均の差は0ではない=平均の差が異なる」が採択されました。
RCTを行ったことで、メールマーケティングの効果が正しく測れるようになり、またt検定を用いてその差が有意であることもわかりました。
1つ気になることは、t.test() の引数が、var.equal = TRUE となっていることです。
これは、「男性向けメール配信あり」と、「メール配信なし」、それぞれの購入金額の分散が同じことを仮定していることを示しています。
これについては特に書籍内で検定を行っていないので、手元で等分散性の検定を実行してみます。
var.test(mens_mail, no_mail)
F test to compare two variances
data: mens_mail and no_mail
F = 2.3473, num df = 21306, denom df = 21305, p-value < 2.2e-16
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
2.285110 2.411204
sample estimates:
ratio of variances
2.34731
# 等分散性の検定の実行
alternative hypothesis: true ratio of variances is not equal to 1
これは、対立仮説が、母分散の比が1ではないということを表しています。
ここで、「p-value < 2.2e-16」とp値がかなり小さい値になっていることから帰無仮説が棄却され、対立仮説が採択されます。
これについて、書籍内容とは異なる結果となってしまったように思えますが、どう考えれば良いのでしょうか。。。